iRODS ist ein Speichersystem für ihre Forschungsdaten zur Langzeitarchivierung, das von Ihren normalen Verzeichnissen in Linux oder Windows getrennt ist. In iRODS werden Verzeichnisse als ‚Collections‘ bezeichnet und sie können weitere Collections (Unterverzeichnisse) oder Datenobjekte (Dateien) enthalten. In der Praxis können Sie der Einfachheit halber Collections und Daten als Verzeichnisse und Dateien behandeln. Dateien und Ordner in Ihren lokalen Verzeichnissen können in das entfernte iRODS-Dateisystem, das das ZDV zur Verfügung stellt, archiviert (kopiert) werden. Die Archivierung erfolgt, indem Sie zunächst ein Verzeichnis (eine Collection) im entfernten Pfad erstellen und dann Ihre lokalen Dateien und Verzeichnisse in den entfernten Pfad in iRODS kopieren.
Ein großer Vorteil von iRODS ist, dass Sie Ihre Daten mit Zusatzinformationen (Metadaten) versehen können. Ihre Daten werden mit wenigen Metadaten (Datum, Ersteller, …) versehen, denen Sie weitere zusätzliche hinzufügen können/sollten (z.B. Titel). Ein weiterer Vorteil ist, dass Daten über sog. ‚Tickets‘ weltweit zum Download veröffentlicht werden können.
Die archivierten Dateien können Jahre später zurückkopiert oder heruntergeladen werden. Die Archive können privat sein und nur langfristig gespeichert werden, sie können auf Forschungsgruppen beschränkt sein oder öffentlich zum Download angeboten werden.
Die Archivierung in iRODS ist derzeit über die Kommandozeile von den ZDV-Linux-PCs, die Terminal-Server linux.zdv.uni-mainz.de und den Supercomputern MOGON II/MOGON-NHR möglich. MOGON hat auch ein spezielles iRODS-Wiki. In Zukunft wird es neue und benutzerfreundlichere Möglichkeiten für den Zugang zu iRODS geben. Derzeit können nur Benutzer mit einem Universitätskonto iRODS nutzen. Wenn Ihr aktueller Arbeitsrechner nicht über eine Standard-ZDV-Linux-Installation verfügt, können Sie per SSH auf die Linux-Server zugreifen. Von dort aus können Sie die verfügbaren iRODS iCommands zum Archivieren von Daten verwenden. Auch private PCs mit einer iRODS iCommand Client-Installation können auf das ZDV iRODS Archiv zugreifen.
In Ihrem Heimatverzeichnis sollte es die Datei irods_environment.json im versteckten Verzeichnis .irods mit folgendem Inhalt geben:
{
"irods_authentication_scheme": "pam_password",
"irods_client_server_negotiation": "request_server_negotiation",
"irods_client_server_policy": "CS_NEG_REQUIRE",
"irods_encryption_algorithm": "AES-256-CBC",
"irods_encryption_key_size": 32,
"irods_encryption_num_hash_rounds": 16,
"irods_encryption_salt_size": 8,
"irods_host": "irods.zdv.uni-mainz.de",
"irods_port": 1247,
"irods_user_name": "FILL IN YOUR USERNAME HERE",
"irods_home": "/zdv/home/FILL IN YOUR USERNAME HERE",
"irods_zone_name": "zdv"
}Vergessen Sie nicht, Ihren korrekten Benutzernamen einzugeben. Geben Sie dann den Befehl „iinit“ und Ihr JGU-Passwort ein.
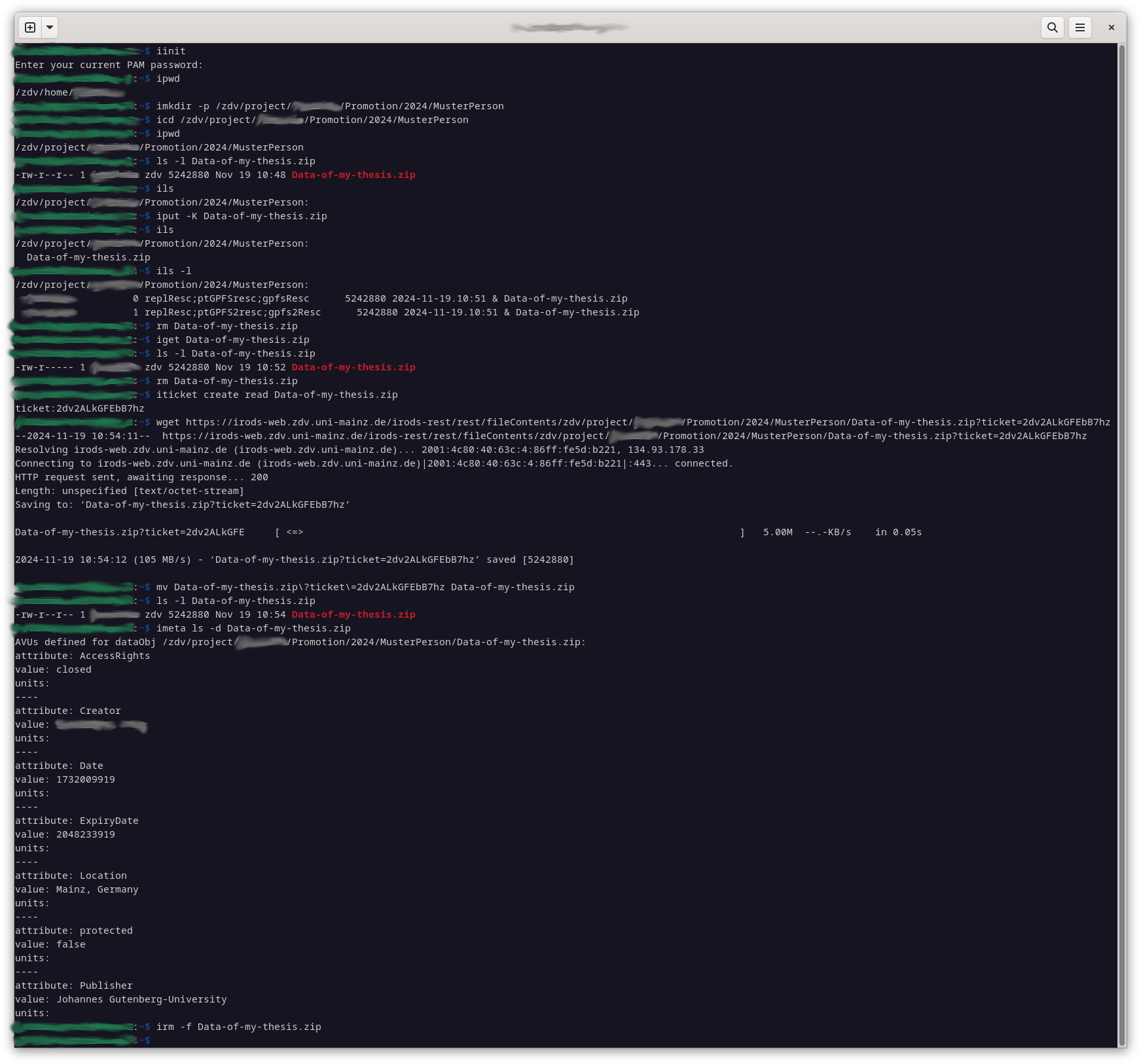
Hier ist eine kurze Zusammenfassung der wichtigsten iRODS-Befehle mit einigen wichtigen Befehlszeilenparametern. Beachten Sie, dass sie mit einem ‚ i ‚ beginnen:
| Command | Parameters | Description |
|---|---|---|
ipwd | Ausgabe des aktuellen iRODS-Arbeitsverzeichnis (Collection) | |
ils | -l, -L, -A, -r | Auflisten des iRODS Verzeichnisses (-l: mit Details; -L: mehr Details; -A: ACL, -r rekursiv) |
icd | <target path> | Aktuelles iRODS-Verzeichnis in den Zielpfad ändern |
imkdir | -p <target path> | Ein neues Verzeichnis erstellen (-p: vollständigen Pfad mit darüberliegenden Verzeichnissen erstellen) |
iput | -K, -r, –metadata | Dateien/Verzeichnisse hochladen, (-K: Prüfsummen berechnen und validieren; -r: rekursiv, –metadata Beschreibungen der Daten hinzufügen: „Title;Mein Titel;;Description;meine Beschreibung;;“) |
iget | -r, -f <target path> | Herunterladen von iRODS-Zieldaten in den aktuellen lokalen Pfad, -r rekursiv, -f überschreiben |
iticket | create read <target path> | Ein Ticket für das Herunterladen von Dateien aus dem Internet erstellen. |
imeta | ls -d/-C <file/dir> | Auflisten der Metadaten einer iRODS-Datei oder eines Verzeichnisses. |
imeta | set -d/-C <file/dir> Key „Value“ | Hinzufügen/Aktualisieren von Metadaten zu einer iRODS-Datei oder einem Verzeichnis (z. B. mit Key = „Title“, „Value“ = „Mein Titel“) |
Hier ist eine kurze Zusammenfassung unserer iRODS-Wrapper-Befehle, die den Archivierungsprozess von Forschungsdaten vereinfachen. Beachten Sie, dass Wrapper mit einem ‚ i_ ‚ beginnen, im Gegensatz zu reinen iRODS-Befehlen, die mit ‚i‘ beginnen:
| Command | Parameters | Description |
|---|---|---|
source /usr/local/bin/i_init.sh | For linux.zdv.uni-mainz.de | Initialisiert iRODS und zeigt nach jedem folgenden Befehl das aktuelle Remote-iRODS-Verzeichnis an. |
i_exit | Löscht das aktuelle iRODS-Fernverzeichnis und bereinigt die lokalen Einstellungen. | |
i_archive | <local file/dir path> <local .json metadata file path> | Lädt das 1. Argument in das aktuelle Remote-iRODS-Verzeichnis/die aktuelle Remote-Sammlung hoch und fügt die Metadaten der .json-Datei des zweiten Arguments zu allen hochgeladenen Dateien hinzu. |
i_metaupdate | <remote iRODS file/dir path> <local .json metadata file path> | Aktualisiert das (erste Argument) entfernte iRODS-Verzeichnis/die entfernte iRODS-Sammlung und aktualisiert die Metadaten (zweites Argument) unter Verwendung der .json-Datei. |
i_publish | <remote iRODS file/dir path> | Erzeugt ein iRODS-Web-Download-Ticket und Links für alle Dateien im Pfad (erstes Argument). Jeder kann die Links verwenden, um die Dateien herunterzuladen. |
i_ticketget | <remote iRODS file/dir path> | Druckt das iRODS-Ticket eines entfernten iRODS-Pfads, falls vorhanden. |
i_downlinkget | <iRODS Ticket> | Verwendet das iRODS-Ticket und druckt die öffentlichen Web-Download-Links. |
Ein vereinfachtes Verfahren zum Archivieren von Forschungsdaten würde die vereinfachten Wrapper verwenden und wie folgt aussehen:
source /usr/local/bin/i_init.sh für die Systeme linux.zdv.uni-mainz.de
Stellt die Wrapper-Befehle zur Verfügung und initialisiert iRODS
imkdir -p /zdv/home/MUSTERPERSON/project123/
erstellt einen neuen entfernten iRODS-Pfad, in den die Daten kopiert werden;
icd /zdv/home/MUSTERPERSON/project123/
ändert das aktuelle entfernte iRODS-Verzeichnis in das neu erstellte;
i_archive /fullpath/some.file metadata.json
archiviert eine lokale Datei some.file in den aktuellen entfernten iRODS-Pfad, indem es sie kopiert und die Metadaten aus den metadata.json-Dateien übernimmt.
i_publish /zdv/home/MUSTERPERSON/project123/some.file
erstellt eine Ticketnummer (z.B.: ABCDEFG123456890) und druckt den generierten Web-Download-Link.
Metadaten werden von iRODS als Triplets akzeptiert (Attribute [i.e: Title], Value [i.e: „Research Data from X publication“],, Unit [meist immer leer gelassen]).
Die ersten beiden Felder Attribute und Value sind Pflichtfelder und dürfen nicht leer sein, die Unit ist optional.
Sie können jeder entfernten iRODS-Datei und jedem Verzeichnis nach dem Hochladen manuell Metadaten hinzufügen, indem Sieimeta set -d some.file Title "My research data from Publication X"
Dies wäre sehr aufwändig und zeitraubend, daher empfiehlt es sich, eine .json-Metadaten-Datei für alle Dateien und Verzeichnisse eines einzelnen Archivbaums zu definieren.
i_archive some.file metadata.json
Kann verwendet werden, um Ihre lokalen Dateien mit Metadaten auf einmal hochzuladen.
i_metaupdate /zdv/home/MUSTERPERSON/project123/some.file metadata.json
Kann verwendet werden, um eine einzelne entfernte Datei/Verzeichnis mit Metadaten zu aktualisieren.
Dieses flache metadata.json-Beispiel benötigt einen minimalen Satz von Metadaten-Attributen:
{
"Title":"",
"ResourceType":"",
"Project":"",
"Keywords":"",
}
{
"Title":"My Scientific Data from XYZ publication",
"ResourceType":"Tables, Texts, Images",
"Project":"BMBF-12345, DFG-67890",
"Keywords":"Thermodynamics, Simulation, HPC, MPI , XYZ, ,BMBF, DFG",
}
Die folgenden Attribute werden beim Hochladen von Dateien/Verzeichnissen automatisch gesetzt und werden in der .json-Datei nicht benötigt:
Creator, Publisher, Location, Date, ExpiryDate (Date + 10 years), protected (default: “false”) .
Die folgenden Attribute werden in Ihrer .json-Metadaten-Datei empfohlen:
{
"Title":"",
"ResourceType":"",
"Project":"",
"Keywords":"",
"Contributor":"",
"Reference":"",
"License":""
}
{
"Title":"My Scientific Data from XYZ publication",
"ResourceType":"Tables, Texts, Images",
"Project":"BMBF-12345, DFG-67890",
"Keywords":"Thermodynamics, Simulation, HPC, MPI , XYZ, ,BMBF, DFG",
"Contributor":"Co-author1, Co-author2, Co-author3",
"Reference":"",
"License":"GPLX, CC0, CC-BY"
}
Sie können bestätigen, dass die Metadaten eingestellt wurden, indem Sie verwenden:imeta ls -d /zdv/home/MUSTERPERSON/project123/some.file for filesimeta ls -C /zdv/home/MUSTERPERSON/project123/ for directories.
Zusammenfassung von imeta:
| Parameter | Beschreibung |
|---|---|
| add|set|rm|ls|cp | Befehl, siehe die nächste Tabelle für Details (ls|cp brauchen das AVU Triplet nicht) |
| -d dataObject |-C directory/collection | welches Objekt/Sammlung (Datei/Pfad) abgefragt/bearbeitet werden soll |
| Attribute Value [Unit] | AVU Triplet, in dem die Unit optional ist |
Befehl-Beschreibung:
| Command | Description |
|---|---|
| add | ein AV(U) Triplet hinzufügen |
| set | einen einzelnen Wert setzen |
| rm | ein AV(U) Triplet entfernen |
| ls | vorhandene Metadaten auflisten. Wenn Attribut angegeben wird, werden nur Metadaten des angegebenen Attributs gelistet |
| cp | vorhandene Metadaten kopieren. Benötigt ein Ziel und eine Quelle (e.g. imeta cp -d source -c target) |
Publishing research data:
Für den öffentlichen Zugang muss ein Ticket zum Herunterladen von Dateien erstellt werden.
Mit diesem Ticket und dem Pfad zum entfernten iRODS-Speicherort kann jeder die Informationen und den Inhalt herunterladen.
Die Veröffentlichung bereits archivierter Daten erfolgt mit:
i_publish
i_publish /zdv/project/project123/MUSTERPERSON/some.file
erzeugt eine Ticketnummer (i.e: ABCDEFG123456890) und druckt den erzeugten Web-Downloadlink
Sie können den Veröffentlichungsprozess stattdessen auch manuell mit iRODS-Befehlen durchführen:iticket create read /zdv/project/project123/MUSTERPERSON/some.file
erzeugt eine Ticketnummer (i.e: ABCDEFG123456890) udie verwendet wird, um some.file aus dem Netz herunterzuladen
Dann müssen Sie den Pfad so hinzufügen, dass er wie folgt aussieht: wget https://irods-web.zdv.uni-mainz.de/irods-rest/rest/fileContents/zdv/project/project123/MUSTERPERSON/some.file?ticket=ABCDEFG123456890Data Policy and Licensing
Der „Creator“ ist dafür verantwortlich, dass die Weiterverwendung von Daten Dritter rechtmäßig ist (Urheberrechtsgesetz) und dass mit personenbezogenen Daten korrekt umgegangen wird (DSGVO).
Dies gilt für alle archivierten Daten, auch wenn der „Creator“ nicht mehr an der Universität beschäftigt ist oder wenn die Daten nicht öffentlich sind.
Diese Entscheidungshilfe kann Ihnen helfen zu entscheiden, ob Ihre Daten veröffentlicht werden dürfen.
Wenn Ihre Daten tatsächlich veröffentlicht werden können, gibt es verschiedene Arten von Lizenzen für verschiedene Fälle:
- Software
- Kunst, Bilder, Text, etc.
- Datensätze
Die Anwendbarkeit von CC-BY-Lizenzen für Software wird nicht empfohlen: siehe hierfür auch die CC-Empfehlung und Diskussion. Dasselbe gilt für Datensätze, deren Veröffentlichung unter einer anderen CC-Lizenz als CC0 zweifelhaft ist. Andere Lizenzen für Datensätze finden Sie unter Open Definition Licenses Service.
Proprietäre Dateiformate sollten vermieden werden, da man nicht weiß, ob es die Software zum Öffnen dieser Formate in ein paar Jahren noch gibt. Versuchen Sie, sich an offene Standards zu halten.
Sie können sich an die folgende Adresse unix@uni-mainz.de wenden, um einen Termin mit unserem technischen Support-Team zu vereinbaren. Sie können Ihnen helfen, weitere Fragen zu klären und Sie durch den Prozess zu führen.
Die Archivierung ist für Forschungsdaten gedacht, die Teil einer bereits veröffentlichten Publikation sind. Die archivierten Daten sollen dazu dienen, Forschungsergebnisse zu reproduzieren. Sie können auch veröffentlicht werden, damit sie von anderen genutzt werden können, oder sie können privat gehalten werden, um die Anforderungen von Fördermitteln zu erfüllen. Wenn Sie einen Labor-PC sichern möchten, gehen Sie zu: www.zdv.uni-mainz.de/datensicherung
Um Forschungsdaten zu archivieren, müssen Sie weder die Art und Weise, wie Sie forschen, noch einen Ihrer bestehenden Daten-Workflows ändern. Die Daten können jederzeit im Nachhinein archiviert werden, indem Sie relevante Metadaten und technische Metadaten erstellen und sie dann in das Archiv hochladen. Es ist aber sinnvoll vorher alles gut zu planen, damit der Überblick nicht verloren geht. Dafür wird hier an der JGU RDMO (Research Data Management Organiser) angeboten.
Die Metadaten fassen wesentliche Informationen über die Forschung zusammen wie: Titel, Beschreibung, Typ, Format, Lizenz, Schlüsselwörter, Mitwirkende, Referenz, usw. Die technischen Metadaten beschreiben, was die Inhalte der Dateien darstellen, wie sie im Forschungsbereich verwendet werden, wie sie miteinander in Beziehung stehen und wie sie verarbeitet werden können. All diese Informationen sind für andere nützlich, um die Forschungsdaten zu finden und zu verstehen.
Alle Forschungsdaten einer einzelnen Veröffentlichung, die archiviert werden sollen, sollten in einem einzigen übergeordneten Verzeichnis zusammengefasst werden. Die Daten innerhalb des übergeordneten Verzeichnisses können dann auf der Grundlage einer von den Autoren gewählten logischen Hierarchie in verschiedene Verzeichnisse sortiert werden. Die Metadaten der gesammelten Daten sollten dann definiert werden, d. h. Titel, Beschreibung, Typ, Format, Lizenz, Schlüsselwörter, Mitwirkende, Referenz usw. Technische Beschreibungen der Forschungsdaten (technische Metadaten) sollten ebenfalls vorbereitet und in das übergeordnete Verzeichnis als für Menschen lesbare Dateien wie „.txt“ aufgenommen werden. Diese technischen Metadaten sollten beschreiben, was die Inhalte der Dateien darstellen, wie sie im Forschungsbereich verwendet werden, wie sie miteinander in Beziehung stehen und wie sie verarbeitet werden können. Das übergeordnete Verzeichnis sollte in ein offenes Format komprimiert werden, wenn der Speicherplatzbedarf dies zulässt.
Sobald Sie Ihre Forschungsdaten gesammelt und mit Metadaten versehen haben, können Sie diese Schritte im wiki befolgen, um sie zu archivieren.
Mehrere große Dateien können einzeln archiviert werden, während große Mengen kleiner Dateien, die zum selben Datensatz gehören, in einer einzigen Archivdatei (zip, tar, rar) komprimiert werden sollten. Wenn möglich, sollten alle Dateien desselben Datensatzes in einer einzigen archivierten (komprimierten) Datei zusammengefasst werden. Dies erleichtert das Auffinden vollständiger Datensätze, die gemeinsam verteilt werden sollen.
The data should be available to be copied from either:
- eine vom ZDV zur Verfügung gestellte Linux-Rechnerinstallation [link]
- das Mogon HPC-System der JGU [link]
- ein beliebiger Rechner mit angeschlossenen Gruppenspeicher-Netzlaufwerken der JGU [link]
- ein Personalcomputer mit installierten Kerberos-Client-Authentifizierungspaketen
- ein beliebiger Rechner mit SSH-Zugang zu linux.zdv.uni-mainz.de [link] oder dem MOGON HPC-System [link]
- ein Windows-PC, der die Linux-Subsysteme oder virtuelle Linux-Maschinen verwendet.
Der Quellcode, der zur Verarbeitung, Erzeugung oder zum Verständnis Ihrer Forschungsdaten benötigt wird, sollte mit den Daten archiviert werden. Zusätzlich kann auf eine Platform wie Gitlab oder Github verwiesen werden, wo der Code weiterentwickelt wird.
Standardmäßig werden die Daten nach dem Hochladen 10 Jahre lang archiviert.
Für die Archivierung von Datensätzen über 1 TB wird empfohlen, sich mit uns unter forschungsdaten@uni-mainz.de in Verbindung zu setzen, um Ihnen zu helfen, eine reibungslose Leistung und Stabilität während des Archivierungsprozesses zu gewährleisten. Wenn die archivierten Datensätze über HTTP-Schnittstellen abgerufen werden sollen, wird eine maximale Größe von 5 GB pro Datei empfohlen. Weitere Beschränkungen und eventuell anfallende Kosten finden Sie auf den Seiten des ZDV.
Derzeit gibt es keine Begrenzung für die Anzahl der zu archivierenden Dateien. Nach Möglichkeit sollten alle Dateien desselben Datensatzes in einer komprimierten Datei zusammengefasst werden. Dies erleichtert das Auffinden eines kompletten Datensatzes, der zusammengehören soll.
Um anderen Nutzern den Zugang zu Ihrem Forschungsdatenarchiv zu ermöglichen, müssen Sie folgende Schritte ausführen [Link].
Ihre Forschungsdaten können während des Archivierungsprozesses oder danach in folgenden Schritten veröffentlicht werden [Link].
Zunächst müssen Metadaten erfasst werden, z. B. Titel, Beschreibung, Typ, Format, Lizenz, Schlüsselwörter, Mitwirkender, Verweis usw.Nachdem Sie diese und andere hilfreiche beschreibende Felder definiert haben, können Sie diese Schritte [Link] befolgen, um Metadaten hinzuzufügen.
echnische Metadaten müssen vom Eigentümer der Forschungsdaten erstellt werden. Technische Beschreibungen der Forschungsdaten sollten dann als menschenlesbare Dateien wie „.txt“ neben den normalen Daten enthalten sein. Diese technischen Metadaten sollten beschreiben, was der Inhalt der Dateien darstellt, wie sie im Forschungsbereich verwendet werden, wie sie miteinander in Beziehung stehen und wie sie verarbeitet werden können.
Unter normalen Umständen ist das Archiv dazu gedacht, unveränderliche Daten über Jahrzehnte aufzubewahren. Die archivierten Forschungsdaten können jedoch in bestimmten Fällen aktualisiert werden, um bestehende Dateien hinzuzufügen oder zu ändern. Dies kann der Fall sein, wenn versehentlich falsche Daten hochgeladen werden oder wenn sich die zugrunde liegende veröffentlichte Forschung ändert. Forschungsdaten, die langfristig archiviert wurden, um staatlichen oder finanziellen Anforderungen zu entsprechen, können und sollten nicht gelöscht werden.
iRODS verwendet „Ressourcen“ zur Archivierung der Sammlungen (Verzeichnisse) und Datenobjekte (Dateien). Die Ressourcen sind hierarchisch organisiert. Das iRODS-Archiv des ZDV verfügt derzeit über eine zusammengesetzte Ressource, die aus zwei GPFS-Dateisystemem an unterschiedlichen Orten besteht. Auf jedem dieser Dateisysteme wird eine Kopie der Daten gespeichrt. Um Kosten zu sparen, ist geplant eine Kopie auf Tape auszulagern.